更新時(shí)間:2025-04-02來源:網(wǎng)絡(luò)
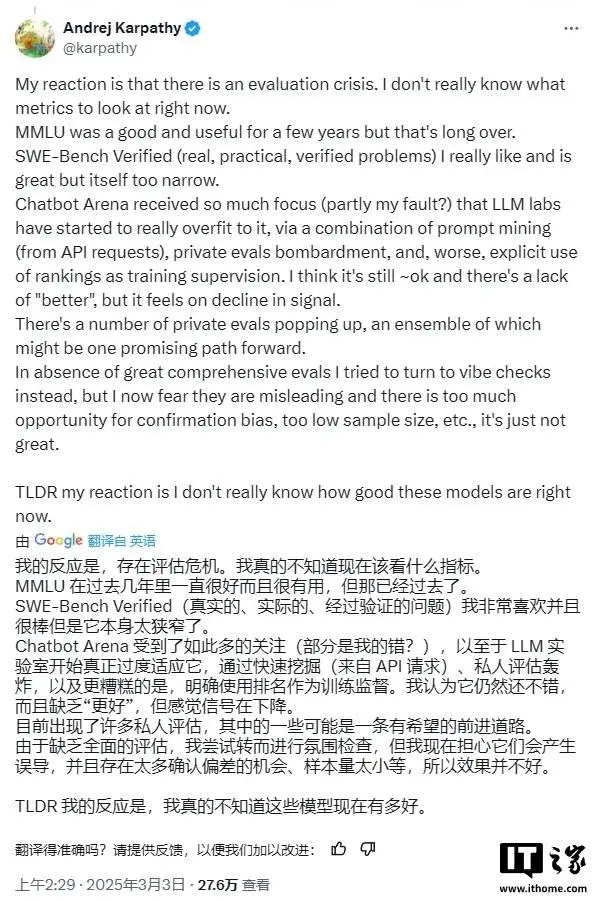
研究背景
當(dāng)前科技發(fā)展迅猛,人工智能的性能測(cè)試成為了焦點(diǎn)。上周,加州圣地亞哥分校的Hao人工智能實(shí)驗(yàn)室選擇了《超級(jí)馬力歐兄弟》這款經(jīng)典游戲,用它來測(cè)試AI的能力。過去,游戲一直是評(píng)估AI成就的工具,這次用馬力歐游戲來測(cè)試,有助于我們更全面地了解AI的表現(xiàn)。
實(shí)驗(yàn)室長(zhǎng)期專注于AI領(lǐng)域的深入研究,這次他們別具一格地挑選了游戲作為實(shí)驗(yàn)平臺(tái),意在在新的環(huán)境中挖掘AI的潛能。這一研究有望為AI的未來發(fā)展帶來新的洞見和思路。

測(cè)試方法
這次測(cè)試并未采用1985年發(fā)布的《超級(jí)馬力歐兄弟》的原始版本。游戲是在模擬器上運(yùn)行的,并且通過一個(gè)我們自主研發(fā)的框架與人工智能系統(tǒng)相連。這個(gè)框架使得AI能夠操控馬力歐。此外,實(shí)驗(yàn)室還向AI輸出了基礎(chǔ)操作指令,例如“注意前方有障礙或敵人,請(qǐng)向左移動(dòng)或跳躍以避開”,并且還提供了游戲截圖。
AI能夠以代碼形式控制馬力歐。這一過程猶如為AI安排了一場(chǎng)“考試”,目的是觀察其在游戲環(huán)境中的問題解決能力。借助嚴(yán)格的測(cè)試手段,實(shí)驗(yàn)室得以準(zhǔn)確評(píng)估每個(gè)AI模型在游戲中的實(shí)際表現(xiàn)。
模型表現(xiàn)
在參與測(cè)試的AI模型里,3.7的表現(xiàn)最為出色。它能夠迅速作出反應(yīng),規(guī)劃出行路徑,游戲操作顯得很流暢。排在第二位的是3.5,同樣顯示了不錯(cuò)的游戲技巧,能夠在復(fù)雜環(huán)境中靈活應(yīng)對(duì)。

相較之下,谷歌的1.5 Pro和GPT-4o的表現(xiàn)不盡理想。它們?cè)趹?yīng)對(duì)游戲中的各種情形時(shí),反應(yīng)遲緩,操作不夠精確,因而游戲進(jìn)程和得分都不太令人滿意。
推理與非推理模型差異
在實(shí)驗(yàn)中,我們發(fā)現(xiàn)o1這類推理模型的表現(xiàn)并不如“非推理”模型。通常情況下,推理模型在多數(shù)基準(zhǔn)測(cè)試中表現(xiàn)得更為出色,然而在這場(chǎng)實(shí)時(shí)游戲中,它們卻遭遇了挫折。原因在于,它們需要數(shù)秒鐘的時(shí)間來做出決策。
在《超級(jí)馬力歐兄弟》這款游戲中,時(shí)間把握至關(guān)重要,稍縱即逝的一秒差異,可能導(dǎo)致結(jié)果截然不同。非推理模型因其反應(yīng)迅速,能捕捉到游戲中稍縱即逝的機(jī)遇,因此在游戲中表現(xiàn)更為出色。
游戲測(cè)試質(zhì)疑
盡管游戲在數(shù)十年的時(shí)間里一直是評(píng)估人工智能性能的關(guān)鍵手段,然而,一些專家對(duì)將AI在游戲中的表現(xiàn)直接等同于技術(shù)發(fā)展的做法表示了懷疑。相較于現(xiàn)實(shí)世界,游戲往往更趨于抽象和簡(jiǎn)單,同時(shí)也能為AI的訓(xùn)練提供大量的數(shù)據(jù)支持。
在游戲環(huán)境中,AI的表現(xiàn)或許不能充分展示其在真實(shí)復(fù)雜環(huán)境中的實(shí)力。即便是一些出色的游戲基準(zhǔn)測(cè)試成績(jī),也引發(fā)了人們所謂的“評(píng)估困境”。
后續(xù)思考
盡管對(duì)此有不同看法,看AI操作馬力歐依然挺有意思。未來研究或許能更好地結(jié)合游戲和現(xiàn)實(shí)環(huán)境測(cè)試,全面評(píng)估AI的表現(xiàn)。此外,我們還需考慮如何提升AI在多變復(fù)雜環(huán)境中的適應(yīng)能力。
AI的發(fā)展之路尚且漫長(zhǎng),此次通過游戲進(jìn)行AI測(cè)試僅是初步的探索。我們熱切期待未來能有更多創(chuàng)新和優(yōu)化,讓AI在各行各業(yè)都能展現(xiàn)出其高效潛能。
相關(guān)資訊
其他推薦
